Education Zone | All kinds of general educational insights and modern information

Jaro Education Chembur
Zero-Shot Knowledge Distillation in Deep Networks. Contribute to vcl-iisc/ZSKD development by creating an account on GitHub. Knowledge distillation deals with the problem of training a smaller model (Student) from a high capacity source model (Teacher) so as to retain most of its performance. Existing. Researchers at the Indian Institute of Science, Bangalore, propose Zero-Shot Knowledge Distillation (ZSKD) in which they don't use teacher's training dataset or a transfer. ZSKD is the knowledge distillation algorithm which not required real data. So they generate "Data Impression" samples which contain the teacher network's knowledge and train student. Jaro Education Chembur, , , , , , , 0, Jaro Education Office Photos, www.glassdoor.com, 0 x 0, jpg, Zero-Shot Knowledge Distillation in Deep Networks. Contribute to vcl-iisc/ZSKD development by creating an account on GitHub. Knowledge distillation deals with the problem of training a smaller model (Student) from a high capacity source model (Teacher) so as to retain most of its performance. Existing. Researchers at the Indian Institute of Science, Bangalore, propose Zero-Shot Knowledge Distillation (ZSKD) in which they don't use teacher's training dataset or a transfer. ZSKD is the knowledge distillation algorithm which not required real data. So they generate "Data Impression" samples which contain the teacher network's knowledge and train student., 20, jaro-education-chembur, Education Zone
To solve this problem, a complete zero-shot KD (C-ZSKD) based on adversarial learning has been recently proposed, but the so-called biased sample generation problem limits the. Details of Hyperparameters Used in ZSKD NOTE:- All the experiments are performed using TensorFlow framework. Similar to MNIST, ZSKD outperforms the existing few data knowledge distillation approach (Kimura et al., 2018) by a large margin, and performs close to the clas-sical knowledge.

Source: www.glassdoor.com

Source: www.glassdoor.com

Source: www.glassdoor.co.in
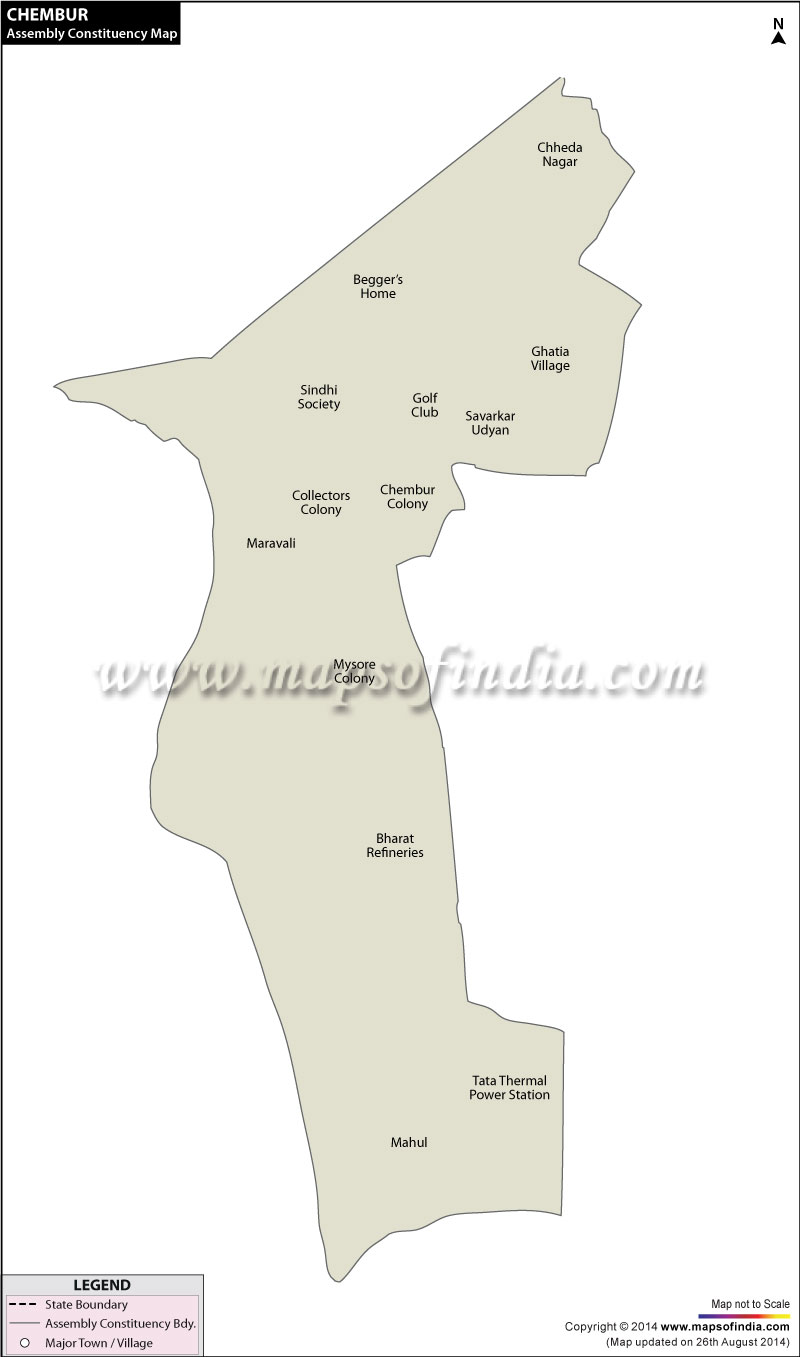
Chembur Assembly (Vidhan Sabha) Election Result 2024 and Constituency Map
Source: www.mapsofindia.com

Jaro Education Office Photos | Glassdoor
Source: www.glassdoor.co.in

Source: www.glassdoor.co.in

Source: www.glassdoor.co.in

Jaro Education Office Photos | Glassdoor
Source: www.glassdoor.co.in

Unveiling the Success Chart of Jaro Education - Dutable
Source: dutable.com

Jaro Education unveils ‘#SuccessKiTayari’ campaign starring Saina Nehwal
Source: sportsmintmedia.com
jaro education on LinkedIn: #chembur #workwithus #walkin #jobopening #
Source: www.linkedin.com

SHEMROCK Preschool - Ashish Theatre Chembur | Preschool in Chembur
Source: www.shemrock.com

SHEMROCK Preschool - Ashish Theatre Chembur | Preschool in Chembur
Source: www.shemrock.com

Jaro Education: Revolutionizing EdTech with Data-Driven Strategies
Source: www.devdiscourse.com

SHEMROCK Preschool - Ashish Theatre Chembur | Preschool in Chembur
Source: www.shemrock.com

Source: www.glassdoor.co.in

Jaro Education Office Photos | Glassdoor
Source: www.glassdoor.co.in

Source: www.glassdoor.co.in

Source: www.slideshare.net

Source: www.glassdoor.co.in
Jaro Education Chembur
Details of Hyperparameters Used in ZSKD NOTE:- All the experiments are performed using TensorFlow framework. Similar to MNIST, ZSKD outperforms the existing few data knowledge distillation approach (Kimura et al., 2018) by a large margin, and performs close to the clas-sical knowledge. Knowledge distillation deals with the problem of training a smaller model (Student) from a high capacity source model (Teacher) so as to retain most of its performance. Existing. We, therefore, dub our method "Zero-Shot Knowledge Distillation" and demonstrate that our framework results in competitive generalization performance as achieved by distillation using. Since we do not use any data samples (either from the target dataset or a different transfer set) to perform the knowledge transfer, we name our approach “Zero-Shot Knowledge Distillation”.